Setting Up a Deployment Pipeline
Kubernetes makes it easy to deploy code, at scale, across a cluster of servers using the kubectl command. Setting up automation to enable continuous integration and continuous delivery (CI/CD) to manage Kubernetes often requires an entirely new pipeline, different from how we were deploying using Ansible, Chef, Puppet and others. Once you have a
Kubernetes cluster running, kubectl from your team’s machines isn’t going to cut it (nor will helm install etc). Instead code should be delivered through automation. On each build, code changes should be analyzed, tested, dual reviewed, and then deployed.
Overview on GitOps Pipelines
Automation for delivery is a pretty common practice, and Kubernetes is purpose-built to leverage such a workflow. GitOps is a popular methodology to accomplish this last “deploy” step. A well-designed GitOps workflow means that your CI system doesn’t have access to the cluster at all, eliminating a common security single-point-of-failure.
A Minimal GitOps Pipeline
There are a few key tenets of GitOps:
-
Once GitOps is in place, all user-executed kubectl access is read-only
-
The only way to modify objects in the cluster is by committing the configuration to a Git repository.
Push vs. Pull
There are two distinct varieties of deployment methodologies to consider here, push-based and pull-based. In a Push-Based workflow, a CI service uses credentials to perform a kubectl apply to deploy resources to a cluster.
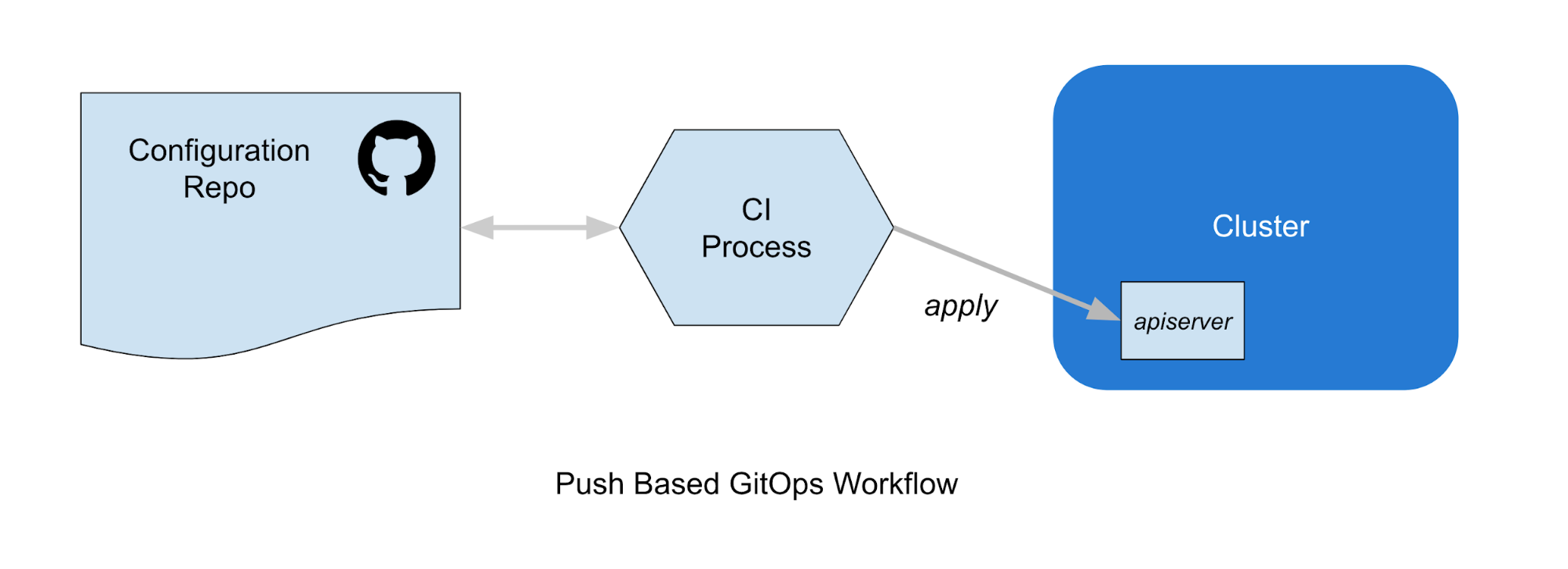
Conversely, in a pull-based workflow, no credentials need to be distributed to an external service. Instead, a GitOps Controller running in the cluster observes the configuration repo, and adds objects to the cluster via a kubectl apply or equivalent.
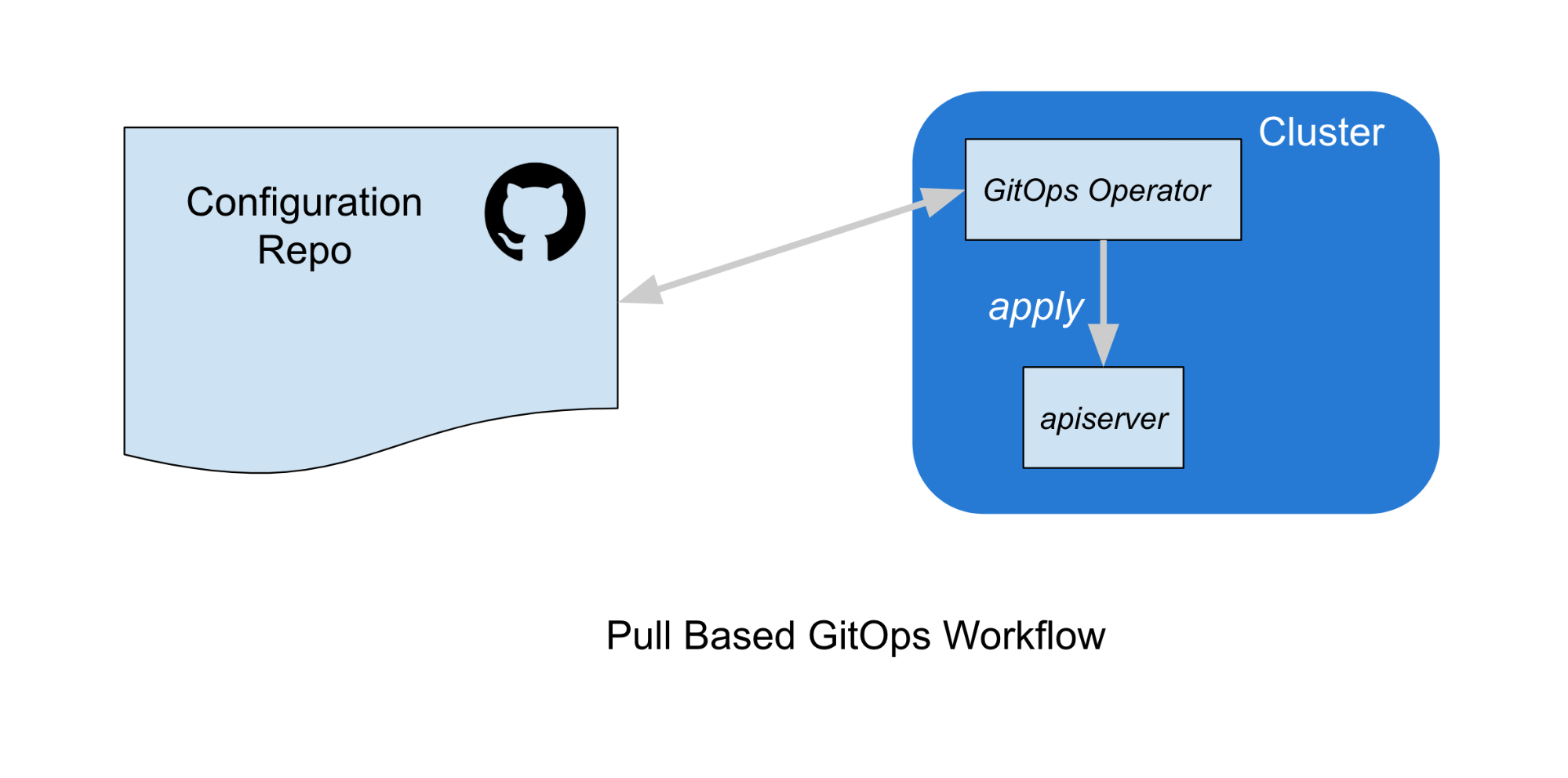
In this article, we’ll focus primarily on these pull-based GitOps workflows. There are some tradeoffs between both approaches, but we prefer pull-based workflows for a few reasons:
-
Write-access credentials don’t need to exist outside the cluster. Instead, Kubernetes can auto-mount a service account token into the controller workload.
-
Rollbacks are managed using existing tools (git), that developers already have expertise in
-
Because the only way to deploy it by committing to git, the git repo is a log of the history of attempted deployments
-
All change requests can be integrated into the workflow that the git provider has (GitHub Checks)
There are a number of excellent OSS GitOps controllers available that integrate with many different VCS systems.
Multiple Clusters
When deploying the same code to multiple clusters, it’s important to think about how you want to handle “promoting” or advancing the change through various clusters. The GitOps tools references in this article are relatively flexible, but repo setup is a decision that must be made early.
Repo based
One repo per cluster. With this setup, each cluster is configured to point to a different git repo. This is useful in cases where there isn’t a lot of common, shared services between the clusters. The downside to this is that CI needs to push YAML to different clusters, and you won’t be taking advantage of common git workflows to promote/merge changes upstream.
Branch based
One shared repo for all clusters, each cluster gets a branch. This is useful for environments/clusters such as “production” and “staging”. In this scenario, CI can push the YAML to the staging branch, and then, once validated, a PR can be made to merge the staging branch into the production branch. This allows a manual promotion event, and it’s easy to see what’s not deployed to production.
Directory based
One shared repo/branch for all clusters, each cluster gets a subdirectory. This is similar to the repo based approach, but in a shared repo.
Kustomize/Overlays based
One shared repo/branch/directory for all clusters, each cluster has a kustomization overlay to apply. Now that kustomize is built into kubectl, some GitOps tools have native support for it. In this scenario, all clusters use the same repo, but they look for a specific overlay path/name to deploy.
Setting Up a GitOps Pipeline
When it finishes building, the CI system will push images to a registry and Kubernetes YAML to a git repository. A GitOps controller, running in the cluster, will detect these changes and automatically apply them. Using a VCS repo as the source of truth for your production infrastructure has a number of benefits.
There are several distinct processes you need to solve to be able to automatically deploy to Kubernetes in this way. And there are a lot of tools available to solve this, so let’s break down each category and discuss some tools.
Image Registry
Before deploying to a Kubernetes cluster, the CI process should create container images and push them to the local registry. It’s recommended to run an image registry locally (even in the same Kubernetes cluster). This gives you the benefit of making these images not accessible outside of the cluster. Popular image repositories that can be deployed as Modern On-prem applications themselves include Harbor and Artifactory. The registries can support private images (credentials required) and also full vulnerability scanning. Before pulling images into a cluster, validate that all security scanning has been completed and the results are acceptable.
Continuous Integration
When developers commit code and it’s merged, a Continuous Integration process should automatically start which, if successful, ends when the GitOps tool running in-cluster deploys the final manifests and images. There are many CI tools that can be deployed and managed using Modern On-prem tools, including CircleCI Enterprise, TravisCI Enterprise, and Jenkins X.
Testing
A GitOps pipeline should include a step where tests are run before the GitOps workflow is triggered. This should happen in CI. When setting up a full end-to-end workflow to deploy software, reliance on testing is critical. In additional to common tests, we recommend that a set of Contract Tests and recommend Pact to manage these tests.
Deployment
A core part of a GitOps pipeline is the in-cluster component that synchronizes the desired manifests from the VCS repo to the cluster. There are several OSS tools that are easy to get started with here.
Flux
Weaveworks has open-sourced the Flux deployment to run in your cluster and sync from git. Flux also can monitor an image repository and deploy changes when a tag is updated. (This is not quite traditional gitops and is not recommended).
ArgoCD
Intuit has open-sourced the ArgoCD operator to run in your cluster and sync from git.
Argo Flux
Weaveworks recently announced a partnership with Intuit to create Argo Flux, a major open source project to drive GitOps application delivery for Kubernetes via an industry-wide community. Argo Flux combines the Argo CD project led by Intuit with the Flux CD project driven by Weaveworks
Environment-Specific Configuration
Most use cases involve deploying to multiple clusters across different regions and stages (dev, staging, prod or us-east-1, us-west-1, etc). Parameterizing the environment-specific configuration is a fundamental problem in Kubernetes, and GitOps is no exception.
Runtime vs. In-Repo
There are two different ways to supply this configuration: at runtime (deployed separately) or in the Kubernetes manifests as part of the deployment.
Supplying the environment specific configuration at runtime involves setting up, configuring, managing and deploying configuration to to a separate tool.
More commonly, (non-sensitive) environment specific config can be supplied to your cluster in basic Kubernetes primitives. The same way you manage Deployments for your workloads, core objects such as configmaps, environment variables and secrets can be used to deliver environment-specific config.
However, secrets aren’t really secret in Kubernetes (yet), so they are just a base64-encoded way to provide data to a pod. For data that’s actually secret, see Secret Management below. Depending on your solution for distributing sensitive information to the cluster, you may want to share this solution with standard configuration also.
The core motivation for per-environment configuration is to reduce duplication between different clusters and environments. Tools that manage this often also function as a packaging tool to manage an aggregation of Kubernetes resources and define how parameters and changes will be applied. The rest of this section discusses the popular tools that can be used to generate the environment-specific YAML from a common, shared base.
Kustomize
Kustomize is the newest entrant to this field, and probably the most different approach. With Kustomize, you decide on a “base” which is the standard yaml. This is often a development setup, because you don’t want to worry about secret management and changing this for each engineer running the stack locally. Then you create an overlay for each of your environments that includes plain yaml to be applied as a strategicMergePatch in your CI tool. Your CI tool will then kustomize build to merge the environment specific overlay (patches) onto the base and produce a new YAML for each environment.
Helm
Helm might seem like a decent choice, but we’re doing GitOps and having an abstraction around the configuration YAML that needs to be deployed is not a good choice. Bottom line: use Helm as an application definition if you want, but don’t deploy with it using the standard Helm toolchain. Some of the GitOps tools have built in support for Helm, and are worth checking out.
Version Control System
Most companies already have this figured out; GitHub, GitLab and Bitbucket seem to be the top contenders. These systems are truly at the center of a GitOps pipeline. The key functionality these provide are “pull request” or “merge request” functionality for change control and auditability of full version histories.
Repo setup for GitOps isn’t something we’re super opinionated about, but we’ll provide a quick overview of how we do it. Each application-code repo contains a directory that either has or can produce the Kubernetes YAML during CI. As the CI process builds the application code, it creates the Kubernetes YAML and makes a commit to the one shared GitOps repo. Regardless of where the project source is, the CI process will commit the deployable YAML to a single repository which is monitored by the in-cluster component.
Third party software is currently split based on where we want it running. For production-critical software such as Prometheus, Elasticsearch, Web application firewalls and more, we have have the same strategy. These applications are managed by Replicated Kots, but the resulting YAML is pushed to the same GitOps repo as our internally-developed applications. Other software such as a Docker image registry, CI tools themselves, and non-production software is still deployed using GitOps, but using a separate pipeline with a separate repo.
Secret Management
A challenge when adopting a GitOps pipeline is secret management. Nobody should commit secrets or sensitive information to a Git repo, even a private one. So, before adopting GitOps, its important to have a plan for how secrets will get deployed/
SealedSecrets
SealedSecrets is a Bitnami Custom Resource Definition (CRD) that makes it possible to commit Kubernetes secrets to a GitHub repo, because they are encrypted with a public key, but the private key that is required to decrypt only exists in the cluster. This is similar in concept to Mozilla SOPS. SealedSecrets are very easy to get started with. This controller doesn’t handle key rotation, dynamic secret generation or anything else. SealedSecrets are simply encrypted secrets, that the controller will decrypt and write a plain text secrets in the cluster as soon as they are applied.
Pros/Cons
-
Con: Turns into regular secrets at runtime. Anyone with read access to secrets in a namespace can get the data. This isn’t a huge blocker, just means you increase the exposure surface area, or you have to be careful with RBAC when distributing read access to team members. We still think it’s better than putting plain secrets in VCS.
-
Pro: kubeseal CLI tool for encrypting secrets is quite friendly.
-
Pro: Supports your existing workflow, just commit more YAML to VCS.
-
Pro: No need to change application code.
Vault
Hashicorp Vault is a more robust secret management solution. This can work at the application layer, providing a way to both provision and distribute secrets to the required components.
Deploying and operating Vault is more work than simple environment variables, but it also provides additional functionality over standard config. When using standard config, you will create the password or other sensitive data and then deploy it. With vault, the sensitive data can be provisioned at runtime. This provides additional security because items such as database passwords don’t exist for a long time. Instead, they are provisioned as needed.
Vault can be used in multiple ways, but it’s possible to enable secret management in Vault by using Init containers. This is a way to modify the Kubernetes YAML to run a specific init process when starting, provisioning the secrets and providing them to the application as standard config. One advantage of this solution is that it works with third party software that hasn’t been written to directly support Vault.
Benefits of GitOps
- No Production write access for anyone
- Provisioning and deprovisioning users does not require a new process
- Easy rollbacks via VCS systems

